It's like looking for a needle in a haystack. Scientists
searching for the gene or gene combination that affects even one plant or
animal characteristic must sort through massive amounts of data.
"Biologists used to
study one gene at time, but now they can look at tens of thousands of genes at
once." Xijin Ge said. Just one experiment to analyze gene expression can
produce one terabyte of sequence data. "That's a little beyond many
biologists' comfort zone."
He leads the
bioinformatics research group, which provides the expertise that SDSU plant and
animal scientists need to uncover how genes and proteins affect cell functions.

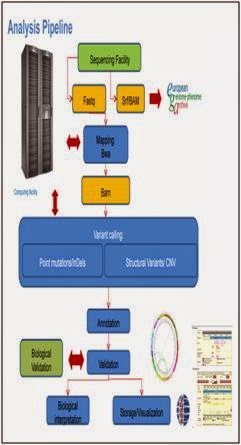
Setting up the
experiments
Typically, scientists consult
with their colleagues when planning their studies. After examining what they
want to investigate, the researchers decide which techniques should be used to
obtain data and a plan to analyze the data."It's critical to have the
statistician and biologist working together," noted plant science
professor Fedora Sutton, who worked with Ge on identifying gene interactions
that account for freeze resistance in winter wheat. "He is able to say,
based on statistical rules and regulations, this is where this has to be."
Using the same technique
on one sample is not enough, Sutton pointed out. Multiple samples must be grown
under the same conditions and then analyzed to have biological replicates. Scientist
explained that experiments must be designed to gather biological rather than
technical replicates. Once the technique to gather data is chosen and a plan of
data analyses is created, scientist said, "we can figure out how many
replicates are needed."
Analyzing
megabytes of data
"Bioinformatics is
an important tool to zoom in on the target gene networks," said Xing-You
scientist, who collaborated with scientist to identify genes that are
associated with seed dormancy in weedy rice. Weeds survive adverse environmental
conditions because of strong seed dormancy, scientist explained. "To
devise new weed management strategies, we need to understand the molecular genetics
mechanisms of seed dormancy."
Scientists used a
map-based cloning strategy and then applied bioinformatics tools, such as
statistical tests and clustering, to find the candidate genes. This task
involved looking at more than 30,000 to 40,000 genes, which can produce three
to four million data points, according to the scientist. To determine which
genes are responsible, scientist must first eliminate those data points that
contain noise and then "focus on the reliable signals because we're
looking at so many genes." Sometimes nearly half the data are eliminated.
Visualizing gene
expression
Scientists use
data-mining algorithms to find patterns of interest to the scientists.
Typically, his analysis produces a visual representation of the data that is
statistically significant.
One of Sutton's visuals
was a heat map depicting gene expressions that were increased or up-regulated
in red, those that were shut down or down regulated in green and those
unaffected in black. This allowed her to identify six genes as potential
markers which will then help breeders develop more lines of freeze-resistant
winter wheat.
After identifying the
genes, the researchers "want to piece together the jigsaw puzzle and
figure out the common characteristics of the affected genes," scientists
explained. This will allow us to identify the sub-systems, or pathways, that
are regulated.







No comments:
Post a Comment